
50% Faster CI Pipelines with GitHub Actions


Revamped our CI pipelines with Docker Compose and the new pipeline is 50% faster, reducing wait times & false negatives. No more unstable or long deployments!
Table of Contents
Last year, I [wrote a tutorial on GitHub Actions](https://tracetest.io/blog/integrating-tracetest-with-github-actions-in-a-ci-pipeline) that explained how Tracetest can be run in a CI pipeline. The goal was to demonstrate how Tracetest can be used to test itself, commonly referred to as **"dogfooding"**.
A year later, here are the main issues I noticed:
1. False negatives.
2. Slow build times, often above 30 minutes per run.
3. Not contributor friendly, due to secret credentials.
4. Hard to maintain, due to long YAML files and polluted Docker Hub repository.
5. Multiple deployments per pull request, due to insufficient parallelization.
6. Using Kubernetes and `kubectl port-forward` introduced connection issues.
Let’s explain the problem before showing you the solution!
## The Problem with CI and Kubernetes
When writing the tutorial last year, I only covered how we integrated Tracetest with GitHub Actions CI pipelines.
The CI pipeline works as follows:
1. A Tracetest "integration" instance is permanently deployed, always up to date with the latest code from `main`.
2. Each pull request builds the code, publishes an image to Docker Hub (tagged `kubeshop/tracetest:pr-[the PR number]`), and deploys that image to our Kubernetes cluster.
3. GitHub Actions run the [Tracetest CLI](https://docs.tracetest.io/cli/configuring-your-cli) to perform trace-based tests for the newly committed Tracetest code. To be able to communicate with both "integration" and "PR" instances, we open tunnels with `kubectl port-forward`.
This approach has worked smoothly for the past year. However, as the project grew, builds became slower, and the team began noticing a few pain points.
## The Old GitHub Actions CI Pipeline is…
### **Flaky**
While this pipeline generally works, it requires a lot of manual reruns due to a noticeable amount of false negatives. The main causes of these false negatives are:
1. **We rely on `kubectl port-forward` to establish connections.** These connections are not very stable. They can experience hiccups during runs, causing the tests to fail.
2. **Version incompatibility between "integration" and "PR"**. While we take backward compatibility seriously, we also need to temporarily break things occasionally during development. This means that sometimes new code is not compatible with the `main` code, causing pipeline runs to fail and even causing us to merge with failing tests.
3. **Kubernetes deployments can be slow and unstable**: Kubernetes is ***eventually*** consistent. This means that it’s hard to be sure when a deployment is really ready. Sometimes the cluster needs to autoscale new nodes, which can take as long as 30 minutes to be in the desired state. These long wait times and temporary inconsistencies create false negatives.
### Very slow
This pipeline can take 15 minutes to run at best and up to 30 minutes at worst. Some of the causes for this are:
1. **Deploying to Kubernetes can take a lot of time.**
2. **Not taking advantage of step parallelization.** Additionally, some of the dependencies between steps may be unnecessary.
3. **When measuring the time it takes to pass a pipeline, it is important to consider the need for potential reruns.** If a pipeline has long run times and is prone to flakiness, you may have to wait up to 30 minutes just to receive a false negative caused by a broken `port-forward`. After rerunning the pipeline, you may need to wait another 15 minutes, if you're lucky, adding a total of 45+ minutes to achieve a passing mark. In some cases, it may even take 2 or 3 reruns to pass.
### Hard to share and maintain
This pipeline requires publishing Docker images and deploying them to Kubernetes. This means we need secret keys to run the pipeline. If someone wants to fork the repository, the pipelines fail because credentials are not shared. The same happens for external contributors, even dependable pull requests fail to run.
Publishing these temporary images to Docker Hub not only requires credentials but also pollutes our repository with a large number of `pr-*` images that need to be removed.
Including a large number of steps in a YAML file can make it difficult to follow, and can also increase the likelihood of introducing mistakes while working on it.
Additionally, it becomes increasingly challenging to keep track of the logic behind each step. As the number of steps increases, so does the complexity, and dependencies between those steps can lead to longer run times.
This is what the old pipeline run looks like:
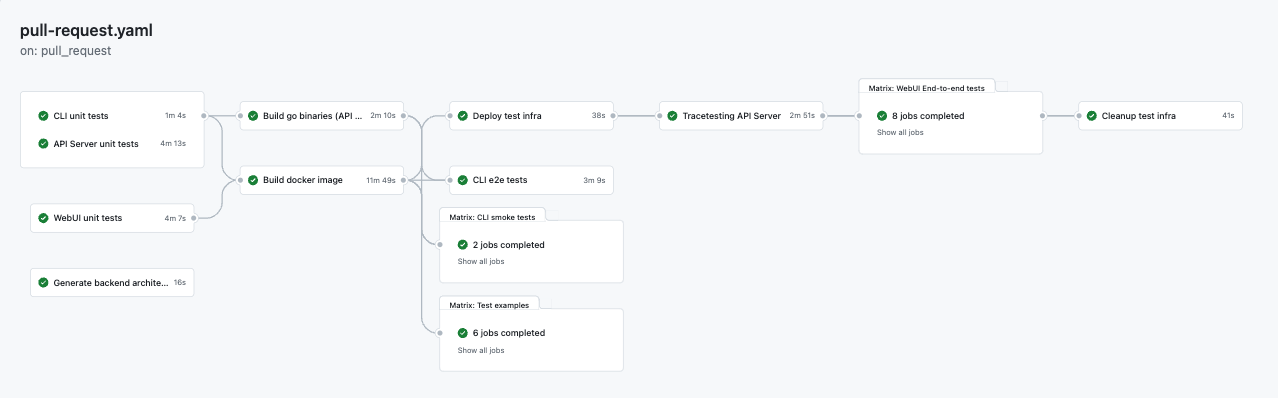
> [*feature(frontend): Adding Analyzer empty state · kubeshop/tracetest@661fb9f · GitHub*](https://github.com/kubeshop/tracetest/actions/runs/5159333362)
## The Solution: Use Docker Compose in CI Pipelines
Several pain points seem to be related to our use of Kubernetes as the deployment mechanism for pull request code. Would it be possible to replace it?
During development, we create a complete working environment locally using Docker Compose. We use this environment to execute manual tests, and we also have a script to run more complex end-to-end tests using Docker Compose.
Using Docker Compose in the CI/CD pipeline means that:
1. **It runs locally, so we don’t need any credentials or tunneling.** We can connect to `localhost`.
2. **We don’t need to wait for long deployments.** Once the Docker Compose stack is up, it’s ready to go, usually in seconds.
3. **Instead of publishing images, we can use `docker save/load` to export/import the image** as a tar file and pass it around as a build artifact. Again, no credentials are needed for this.
### New and Updated GitHub Actions CI Pipeline
This is what our new pipeline looks like today:
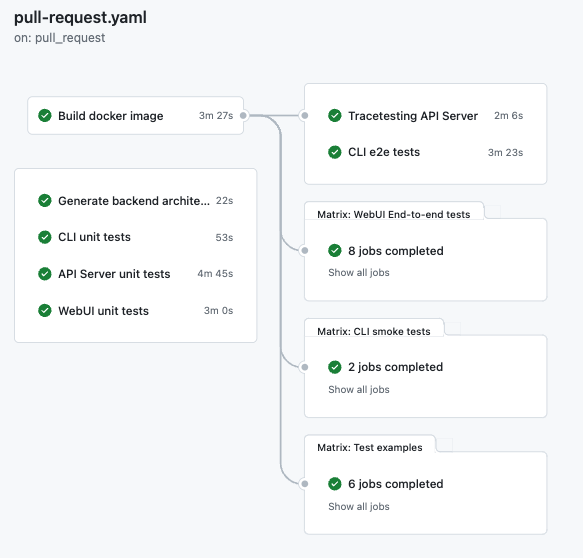
> [*fix(cli): adding skip of version mismatch for the server install cmd · kubeshop/tracetest@3f6f96e · GitHub*](https://github.com/kubeshop/tracetest/actions/runs/5179986062)
You may have noticed that we've made some changes to the pipeline. We've moved it to Docker Compose and improved our parallelization strategy, resulting in a reduction of 1-2 minutes of unnecessary wait time. Here are some examples:
- In the old pipeline, we had to wait for all unit tests to complete before building the Docker image. These tests could take 2-4 minutes to finish. There's no need to wait for them before building the image, so we removed this dependency.
- We had multiple build steps for the Web UI, Go Server, and the Docker image. We couldn't start building the Docker image until the Web UI was built, so there was no parallelization. Splitting them into different steps only added startup overhead. Thus, we merged them into a single `build docker image` step.
## The Conclusion: 50% Faster CI Pipelines
You can check the complete pipeline in [the Tracetest GitHub repository](https://github.com/kubeshop/tracetest/blob/main/.github/workflows/pull-request.yaml).
**This new pipeline takes between 12 and 16 minutes to run**.
- The best case is **3 minutes faster** than the old best case.
- The worst case is **15 minutes faster** than the old worst case — a **50% reduction in time**.
However, most importantly, ever since we began using this new pipeline, we have noticed a significant decrease in false negatives caused by unstable remote connections and unready deployments.
We originally thought that the best solution was to have a single deployment per pull request, so every pipeline step would not need to set up an entire environment. It turned out the best solution was exactly the opposite of that.
Finding the best approach is not always easy, especially in complex scenarios such as a full end-to-end CI/CD pipeline. It's important to keep an eye on issues, take note of problem areas, analyze results, and try out new ideas, even those that might not seem promising at first.
We are eager to hear your feedback and to talk to you. Please share your thoughts on how trace-based testing can help you and what we should do next to improve Tracetest. Have an idea to improve it? Please [create an issue](https://github.com/kubeshop/tracetest/issues/new/choose), [give us a star on GitHub](https://github.com/kubeshop/tracetest), and join our community on [Slack](https://dub.sh/tracetest-community).
.jpg)
.avif)
.avif)